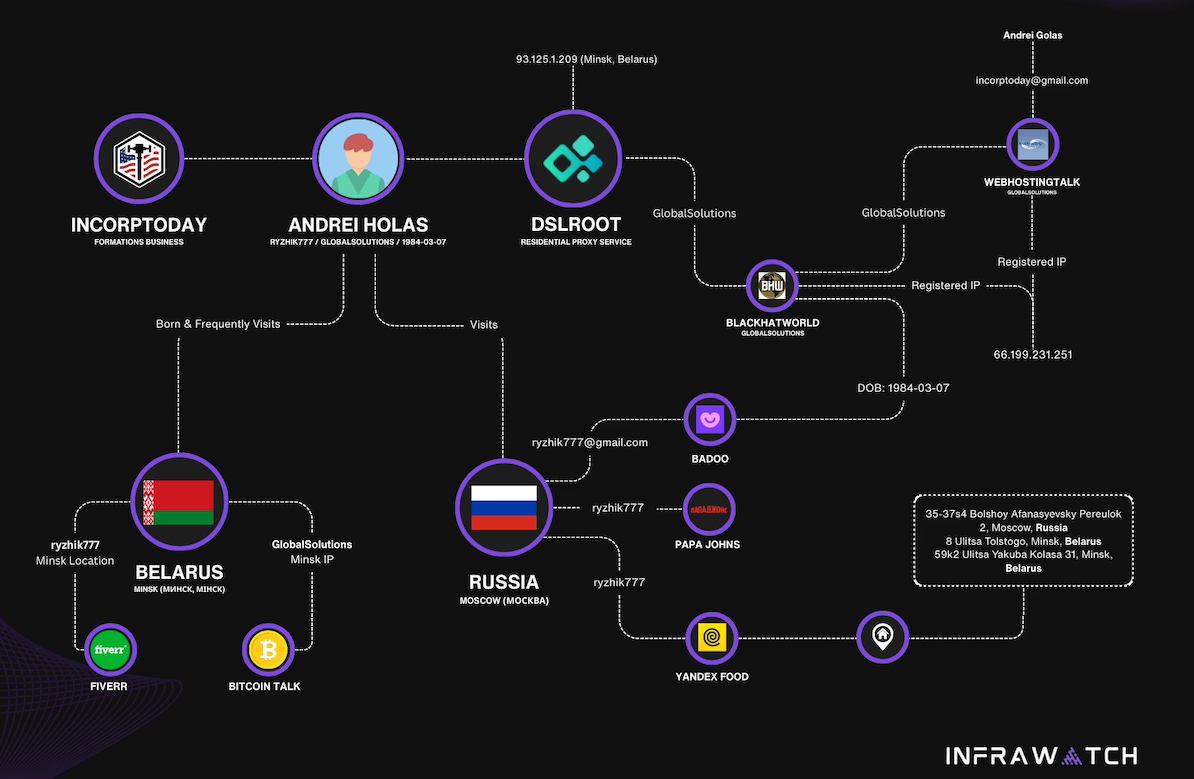
Secure and Robust Watermarking for AI-generated Images: A Comprehensive Survey
arXiv:2510.02384v1 Announce Type: new Abstract: The rapid advancement of generative artificial intelligence (Gen-AI) has facilitated the effortless creation of high-quality images, while simultaneously raising critical concerns regarding intellectual property protection, authenticity, and accountability. Watermarking has emerged as a promising solution to these challenges by distinguishing AI-generated images from natural content, ensuring provenance, and fostering trustworthy digital...